OMLX 让你的 OpenClaw 本地模型速度起飞

最近看到很多博主在 Mac mini 上部署🦞“龙虾”,但哪怕是上万块的设备,也普遍面临一个痛点:巨慢无比,问一个问题要等好几分钟。今天,经过一番折腾,我发现了一个能让 16G 丐版 Mac mini 焕发第二春的开源神器。它不仅能提速数十倍,还能高并发跑千万 3.5 4B 模型,而且速度一点都不慢。
如果你也想拯救手里的 Mac 并在本地玩转 Agent,这篇硬核分享你绝对不能错过。
为什么 LM Studio / Ollama 跑 Agent 那么慢?
很多朋友用 LM Studio 或 Ollama 跑 4B 模型时直接被劝退,测试三个问题甚至要花五分钟。这其实不是 Mac 输出速度慢,而是卡在了最耗时的“提示词处理”(Prefill)阶段。
当我们使用类似 Claude Code 或 OpenCloud 这样的 Agent 时,每次发给 AI 的不仅仅是你的问题,还包含了系统提示词、工具描述、MCP 配置等高达 20K token 的上下文。这 20K token 相当于 15000 个英文单词,这就意味着 AI 每次都要重新“读”一遍这篇万字长文才能开始回答。
在 Mac 上,底层计算是用 CPU 做推理的,处理这种庞大的矩阵计算非常吃力,导致你收到第一个字之前起码要等二三十秒。而且目前主流社区对千问 3.5 的前缀缓存支持还不够完美,导致你第二次、第三次提问时,AI 依然要重复这个漫长的等待过程。
OMLX:专为 Agent 时代设计的推理引擎
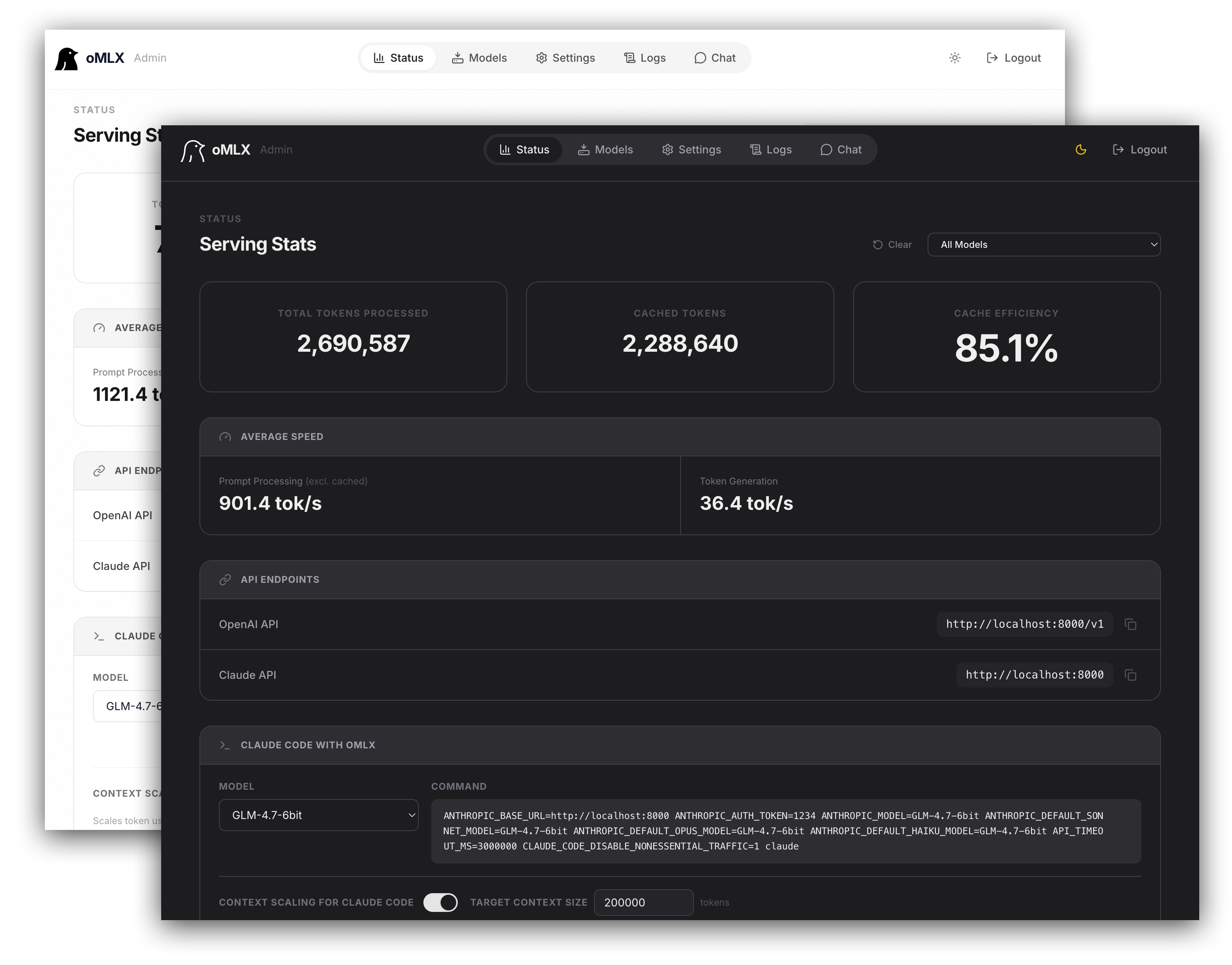
为了解决这个问题,我挖到了一个目前在 GitHub 上只有 140 多个 Star 的宝藏推理服务器:OMLX。传统的开源生态往往假设单用户场景,缺乏 Agent 时代“高并发”的设计灵魂。而 OMLX 的作者用堪称“杀鸡用牛刀”的生产级架构,完美解决了盖版 Mac 的并发瓶颈。
它主要做了以下几点极其聪明的核心优化:
- 前缀缓存 (Prefix Caching):它能把那 19K 不变的系统提示词和工具描述算好的矩阵直接保存下来,下次直接调用,彻底告别重复读题。
- 突破性的 SSD KV 缓存:当应对 100 个 Agent 请求导致内存/显存告急时,OMLX 能把正在排队的缓存存放到容量大得多的 SSD 上。虽然 SSD 速度不及内存,但比起重新计算 20K token 花费的几十秒,这点读取损耗完全可以忽略不计,换来的是近百倍的效率提升。
- 企业级分页缓存 (Paged Cache):这是类似于 VLM 等顶级推理框架引以为傲的技术。如果你开了 10 个 Claude Code 窗口,它们相同的提示词部分只会在内存中保存一份,只有不一样的问题才会被各自单独存储。
OMLX 极简部署与上手指南

OMLX 的体验就像一个简单版的 LM Studio,但把该优化的核心性能全拉满了。
- 一键安装:前往 GitHub 的 Release 页面下载 DMG 文件,直接拖拽安装即可。
- 初始配置:首次启动会进入 Welcome Stream,设定好你的基础目录 (Base Directory)、模型存放路径、端口和 API Key,点击 Start 即可启动。
- 持久化缓存:它的缓存机制非常硬核,即使重启软件缓存依然存在。下次再开一个新 Session 几乎是秒开,缓存命中率极高。(注:当前版本中文界面有小 bug,每次进入需重新点击切换中文)。
- Agent 无缝接入:配置好模型后,OMLX 会自动生成启动 Cloud Code 的命令行参数。直接复制到终端运行,就能自动触发上下文压缩机制,产品细节做得极其到位。
- 硬核基准测试:软件内置了 Benchmark 工具,你可以直观地测试不同量化模型(如 0.8B)在不同硬件、不同并发量下的生成速度,无论是相同提示词还是不同提示词的连续批处理能力,一测便知。
总结
如果你只是偶尔和 AI 聊聊天,现有的工具完全够用,不用折腾。但如果你是一个有追求的极客,想要在本地多开 Claude Code 榨干 Mac 算力,OMLX 绝对是你必须关注的秘密武器。这个引擎未来绝对会火,现在用起来,你就是最早一批吃上螃蟹的人。