封底估算(Back-of-the-Envelope Estimation)

Back-of-the-envelope estimation,中文翻译为“封底估算”或“封底计算”,是一种快速估计或粗略计算的方法,通常在纸巾或白板上进行。它不涉及复杂的数学计算或模型,而是通过直观的方法来估计一个问题的解。
1. 什么是封底估算
封底估算的基本思想是,通过简单的数学公式或粗略的计算来估计问题的解,而不是进行复杂的计算。这种方法可以帮助快速获得一个问题的解的粗略估计,而不必进行详细的分析或建模。封底估算通常用于以下情况:
- 在早期的项目规划阶段,估计项目的成本、时间和范围。
- 在商业谈判中,估计交易的价值或成本。
- 在日常生活中,估计旅行、购物或其他个人开销。
封底估算的优点包括:
- 快速:封底估算可以快速获得问题的解,而无需进行复杂的计算。
- 简单:封底估算只需要简单的数学公式或粗略的计算,而无需复杂的数学模型。
- 直观:封底估算可以直观地表示问题的解,而无需详细的解释。
- 灵活:封底估算可以应对不同类型的问题,并且可以随时调整计算方法。
封底估算的缺点包括:
- 不够准确:封底估算通常不够准确,因为它牺牲了精度以换取速度。
- 容易被误导:封底估算容易被误导,因为它可能会忽略重要的细节或假设。
- 不适用于复杂问题:封底估算不适用于复杂的问题,因为它需要更复杂的数学模型和计算方法。
封底估算是一种有用的工具,可以帮助快速获得问题的解,而无需进行复杂的计算。但是,它的准确性和可靠性取决于问题的复杂程度和假设的合理性。因此,在进行封底估算时,需要谨慎选择计算方法,并确保假设的合理性。
2. 开发工程师应该知道的操作耗时和可用性相关的数据
2.1 了解 2 的幂
面对一个比较大的系统时,尽管数据量会变得非常庞大,但相关的计算归根结底还是基本的数学运算。
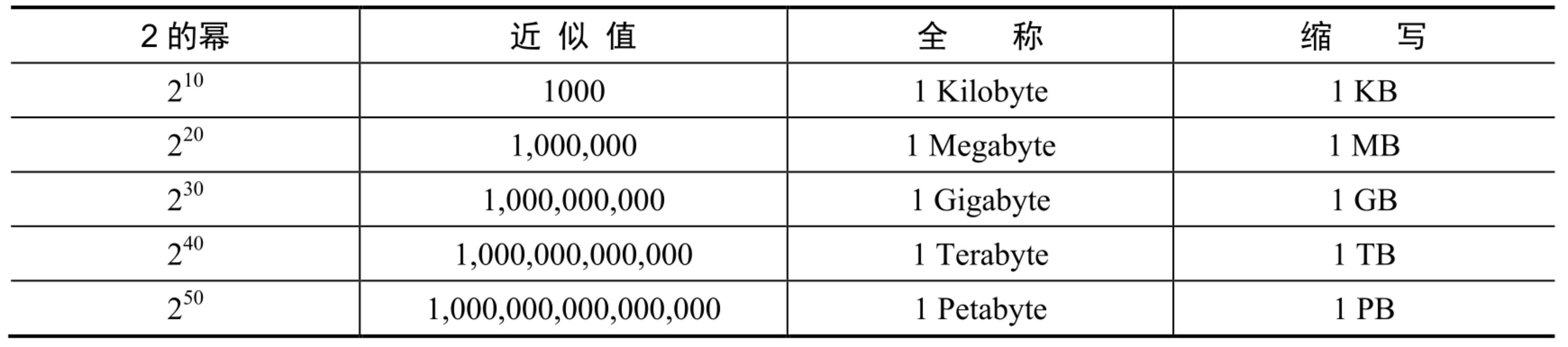
为了获得正确的计算结果,了解 2 的幂所代表的数据量单位非常重要。1 字节(byte)是 8 比特(bit)。一个 ASCII 字符占用 1 字节的内存(8 比特)。
2.2 了解操作耗时
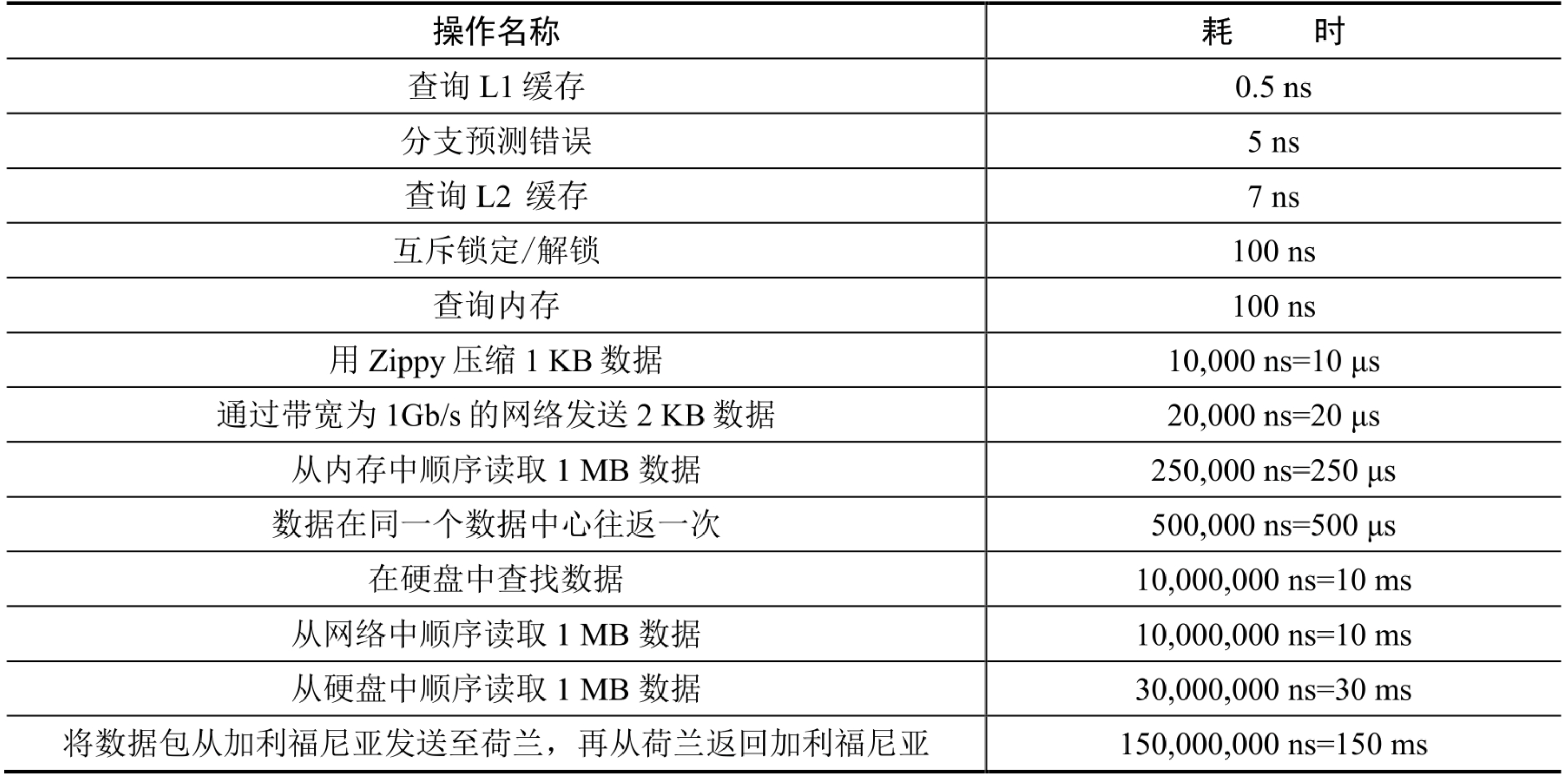
谷歌的 Dean 博士在其 2010 年的文章中揭示了典型计算机操作的时长。随着计算机的速度越来越快,算力越来越强,有一些数字应该已经过时了。但是,通过它们,我们依然可以了解不同操作的耗时。
谷歌的软件工程师 Colin Scott 做了一个工具,可视化地展示 Dean 博士的数据。这个工具在展示时还考虑了时间因素。
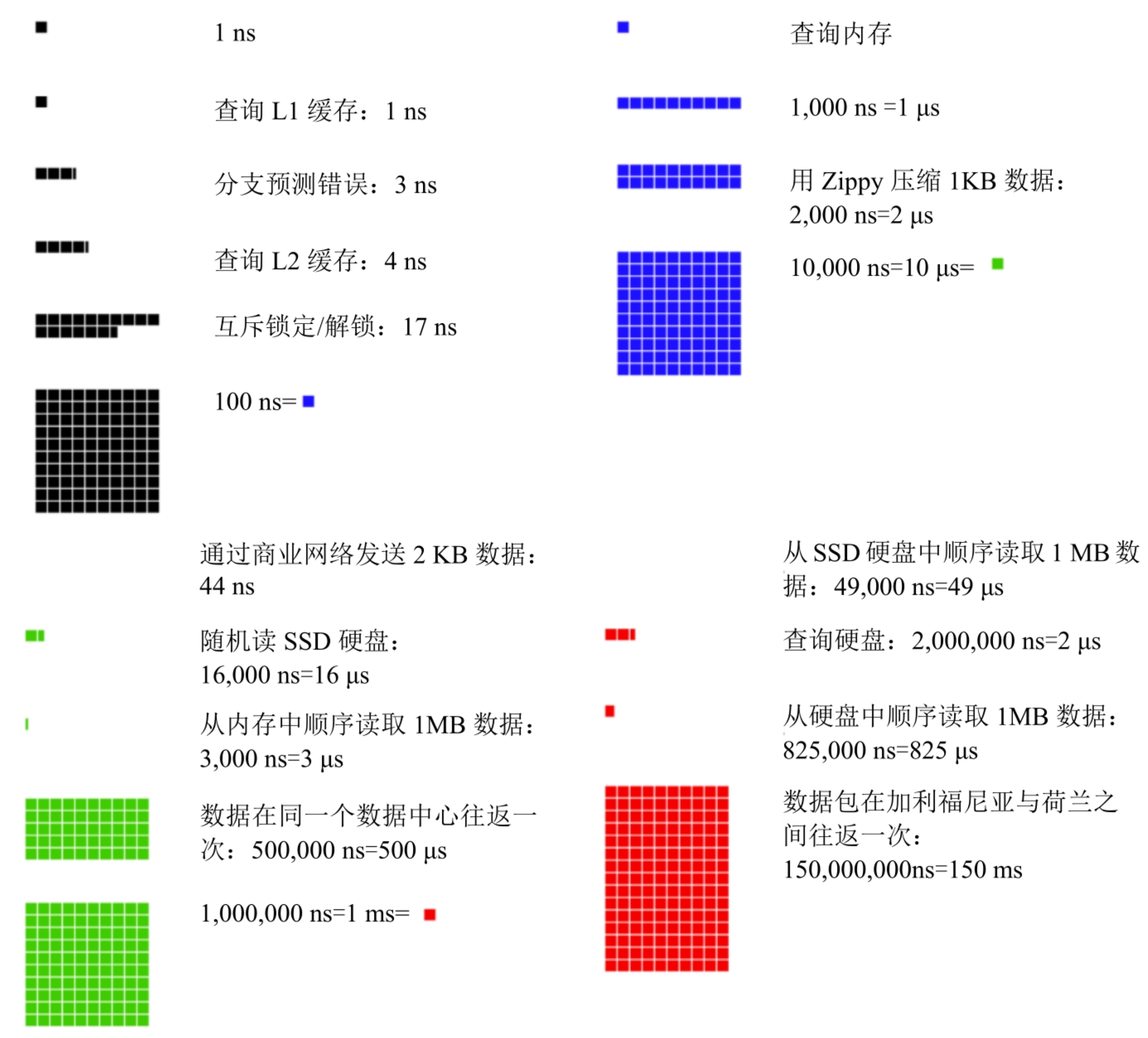
通过分析数据,我们得出如下结论:
- 内存的速度快,而硬盘的速度慢。
- 如果有可能,尽量避免在硬盘中查找数据。
- 简单的压缩算法速度快。
- 尽可能将数据压缩之后再通过因特网传输。
- 数据中心通常位于不同的地区,在它们之间传输数据需要时间。
3. 高可用数据化后的表现
高可用性是指一个系统长时间持续运转的能力。
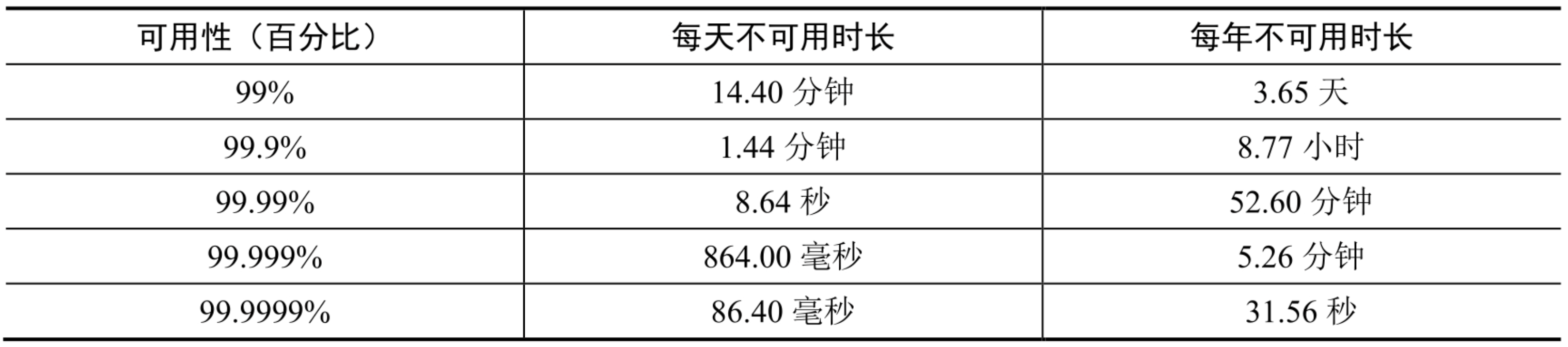
高可用性一般是用百分比来衡量的,100%意味着服务没有不可用的时间,大部分服务的可用性在 99%到 100%之间。
SLA(服务水平协议)是服务提供商普遍使用的一个术语。它是你(服务提供商)和你的客户之间的协议,正式规定了你提供的服务应该正常运行的时间。云服务提供商亚马逊、谷歌和微软把它们的 SLA 设定为 99.9%或以上。(说实话,我觉得 3 个 9 已经很牛逼了)
正常运行时间通常是用小数点后“9”的个数来衡量的。“9”越多则代表可用性越高。
4. 工程师要算的帐
4.1 案例:估算推特的QPS和存储需求
假设
- 推特有3亿月活用户。
- 50%的用户每天都使用推特。
- 用户平均每天发两条推文。
- 10%的推文包含多媒体数据。
- 数据要存储5年。
以下为根据上面的假设而估算出来的一些数据。
- 估算QPS(每秒查询量)。
- 每日活跃用户(DAU)=300,000,000×50%=150,000,000
- 推文QPS=150,000,000×2÷24小时÷3600秒≈3500
- 峰值QPS=2×推文QPS≈7000
- 这里仅估算多媒体数据的存储量
- 平均推文大小,tweet_id:64字节,文本:140字节,多媒体文件:1MB
- 多媒体数据存储量=150,000,000×2×10%×1MB=30TB/天
- 5年的多媒体数据存储量=30TB×365×5≈55PB